使用PyTorch的一些笔记,以防写完就忘,看完API又想起来,长此以往。
torch.nn
torch.nn.LSTM
LSTM中的hidden state其实就是指每一个LSTM cell的输出,而cell state则是每次传递到下一层的「长时记忆」,我总觉得这个名字起的特别别扭,所以总不能很好的理解。下面这张图能更好的说明这些变量的意义。
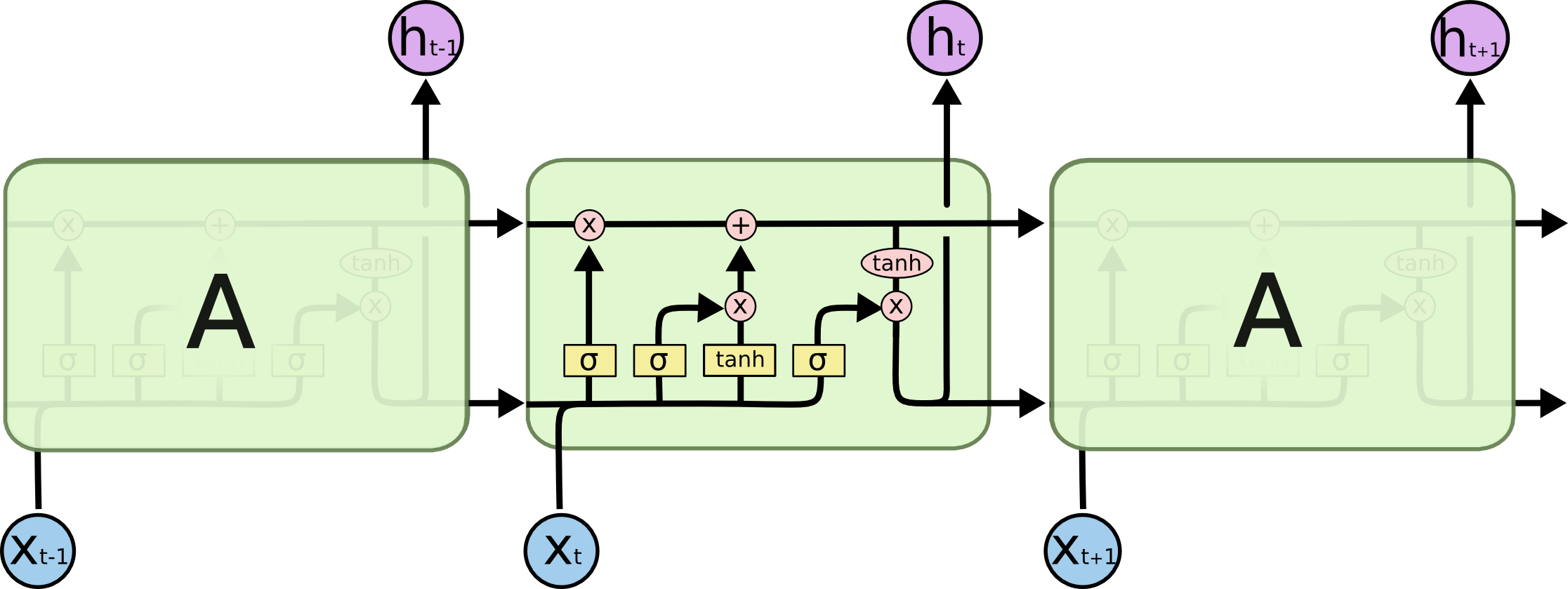
再来简单的回顾一下LSTM的几个公式
其中$h_t$和$c_t$就是所谓的hidden state和cell state了。可以看到LSTM中所谓的output gate,即$o_t$其实是中间状态,它和cell state经过$\tanh$相乘,得到了hidden state,也就是输出值。
PyTorch中LSTM的输出结果是一个二元组套二元组(output, (h_n, c_n))。第一个output是每一个timestamp的输出,也就是每一个cell的hidden state。第二个输出是一个二元组,分别表示最后一个timestamp的hidden state和cell state。因此,如果把h_n和c_n记录下来,就可以保留整个LSTM的状态了。
PyTorch中可以通过bidirectional=True来方便的将LSTM设置为双向,此时output会自动把每一个timestamp的正向和反向LSTM拼在一起。而h_n和c_n的第一维长度会变为2(单向是长度为1)。而且此时有
即正向output的最后一个timestemp(对应LSTM的最后一个cell)的输出和正向的hidden state相同,反向output的最后一个timestamp(对应LSTM的第一个cell)的输出和反向的hidden state相同。
此外,在PyTorch中,LSTM输出的形状和别的框架不太一样,它是序列长度优先的,(seq_len, batch_size, hz),如果觉得不习惯,可以通过batch_first=True来设定为batch_size优先。
