BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
学习一下SOTA语言模型
这篇文章可以称得上是2018年NLP方面一个里程碑式的论文了。当时,BERT模型在GLUE评测榜上横扫其他所有模型,在11个NLP任务上达到最高。尽管这篇论文的阅读笔记在各种博客、论坛等地方都能看到,但我觉得仍然有必要仔细的阅读一遍原文。一来可以加深对论文的理解,二来通过阅读笔记的形式可以更好地记忆这篇文章的细节,不容易忘记。BERT这篇文章通俗易懂,整体结构完整,条理非常清晰,适合所有学习NLP的人阅读。但阅读前需要对Transformer有所了解。
模型结构
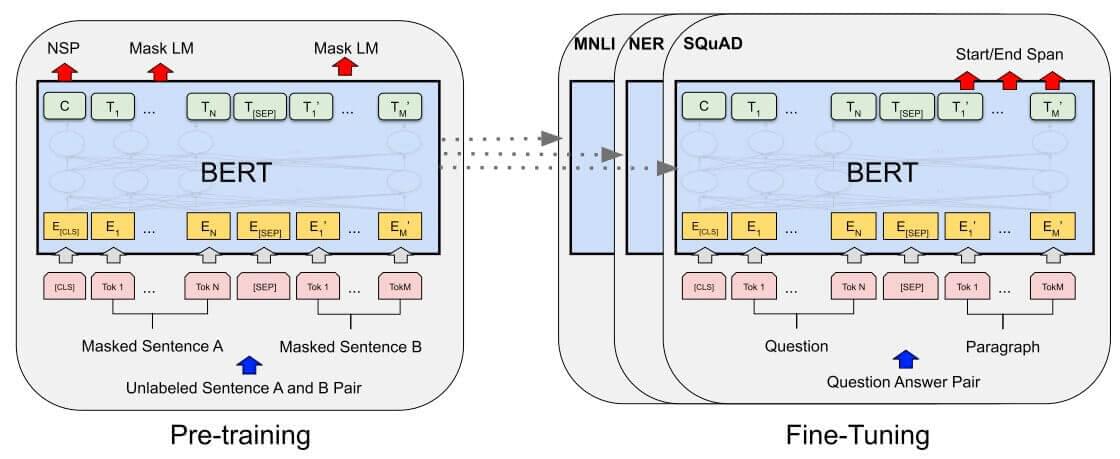
如上图所示,BERT模型几乎完全基于Transformer结构的堆叠,更确切地说,BERT模型是基于Transformer结构的Encoder部分。这也是该模型与GPT模型的最大不同,后者使用的是Transformer结构的Decoder部分,这意味着句子中的每个单词在计算self-attention时只能看到它左边的部分。
简单地回顾一下Transformer结构,它由6层Encoder和6层Decoder组成,Encoder用于将输入转变成某种中间表示形式,而Decoder则从中间表示形式输出具体的序列结果。两者的区别还包括,Encoder的self-attention是双向的,每个单词都会和句子中的所有其他单词做点积。而Decoder的self-attention为了防止提前看到后面的单词,在计算self-attention时会先乘以一个上三角的mask矩阵。
BERT与Transformer的另外一个主要区别是,BERT中的Positional Embedding是由模型自己学习的,而Transformer中则是硬编码的。但BERT这篇论文中没有介绍Positional Embedding具体是如何学习的。
一种显而易见的办法是,单独添加一个Embedding层,然后学习一个$\text{seq_length} \times \text{word_dim}$的矩阵,这样就可以构建一个Lookup表来处理任意位置的Positional Embedding。
最后,BERT的输入由三部分求和得到:单词的Embedding、Positional Embedding以及Segment Embedding,Segment Embedding用于区分输入的两句句子。输入之所以是两句句子主要是训练BERT过程中的Next Sentence Prediction (NSP) 任务,这在后面一节会继续介绍。
训练方法
搞清楚BERT模型的结构之后,下面来看训练BERT的具体方法。BERT通过两个子任务进行训练。1. Masked LM (MLM) 2. Next Sentence Prediction (NSP)
这两个任务是同时进行的,如上图所示。模型的一系列输出中,左侧的NSP标签是NSP任务的输出结果,而后面的所有输出都是MLM任务的输出结果。
Masked LM
该任务相比传统的Language Model任务,多了一个Mask的操作。具体来说,由于BERT使用了双向的Transformer Encoder结构,每个单词都能看到句子中的所有其他单词,因此如果直接使用Language Model任务来训练BERT,那么由于模型已经“看到”了整个句子,因此很容易就能预测出所有的单词。为了解决整个问题,BERT提出了MLM任务来对模型进行训练,就是将句子输入到模型中时,随机的遮掉一些单词,BERT使用[MASK]这个token来代替句子中的原有单词。同时,如果一直使用[MASK]来代替句子中的原有单词,那么在后续对BERT作fine-tuning时由于输入数据不一定含有[MASK],会导致输入空间不一致的问题。BERT并不总是使用[MASK]替换单词。事实上,对于一句句子,BERT首先选择$15\%$的单词。然后对于选中的哪些单词,以$80\%$的概率替换为[MASK],$10\%$的概率随机替换为另一个单词,$10\%$的概率保持不变。
一个可能存在的问题是,这一做法是否会影响BERT对Language Model的学习效果?作者在附录中提到,由于随机替换为另一个单词只占全部数据的$15\% \times 10\% =1.5\%$,因此不会影响Language Model的学习效果。
Next Sentence Prediction
LM任务只能学习句子本身的特征,对于如问答、自然语言推断等NLP任务,需要学习句子之间的关系,BERT提出使用NSP任务来学习句子之间的关系。每一个训练样本中包含两个句子A和B,NSP要求判断B是不是A的后面一句句子。训练样本中$50\%$的数据满足B是A的后续句子,剩下的$50\%$则是随机选择的句子作为B。后续的实验也表明,NSP任务的训练使得BERT在问答、句子推断等任务上取得了很好的效果。
BERT同时使用MLM和NSP这两个任务进行训练。比如以下是两个样本例子:
1.
1 | Input: [CLS] the man went to [MASK] store [SEP] he bought a gallon [MASK] milk [SEP] |
2.
1 | Input: [CLS] the man went to [MASK] store [SEP] penguin [MASK] are flight ##less birds [SEP] |
NSP和MLM是两个不同的分类任务,直接在transformer结构后面接一层全连接,然后再套一个softmax就可以用交叉熵来计算Loss了。训练的总Loss就是这两部分Loss的和。
下游任务
训练好了BERT,怎么把BERT运用到具体的NLP任务中呢?作者建议使用两种办法,feature-base和fine-tuning。feature-base就是固定BERT的参数,直接使用BERT的输出来作为提取的特征,接到其他的模型中。而fine-tuning就是直接在BERT后面接一层全连接+softmax,然后直接在BERT上面跑end-to-end地跑下游任务。作者在论文中说,基本上只需要3-4个epoch就能跑到相当不错的效果了,因此fine-tuning需要的计算开销非常小。并且,由于BERT使用句子对进行预训练,因此对于单个句子的NLP任务,比如句子分类、标注任务,只需要让A等于那个句子,B置空即可。而对于多句句子的任务,可以适当地分配A和B。比如在阅读理解中,可以把A作为阅读材料,B作为问题;对于句子关系判断任务,可以直接将两句句子放到A和B中等。
实验部分这里就不细讲了,简单地说,就是BERT在GLUE评测的12个NLP任务中的11个横扫其他全部模型,总分跃居第一,而且很多任务的准确率相比SOTA甚至有$10\%-20\%$的提升,关于具体的实验结果可以去看原论文。
总结
BERT的提出象征着NLP的一个飞跃式的发展,NLP方面的深度学习方法从此从预训练词向量发展到预训练模型。虽然作者谦虚的表示,BERT的提升最本质的原因只是把GPT的单向Transformer模型改进到双向的Transformer,但是从大量的实验上仍然可以表明,BERT的贡献无疑是十分巨大的。另一方面,BERT的成功还表明了海量无标签文本语料的重要性,催生了后续一大批以更大量文本作为预训练数据的模型的诞生。
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding